
UsingDebugging AI Requests
Debugging AI Requests
To debug the requests sent to AI providers (like ChatGPT or Claude) and their responses, you can enable the 🔵 Info severity level in the settings for Logs & Notifications.
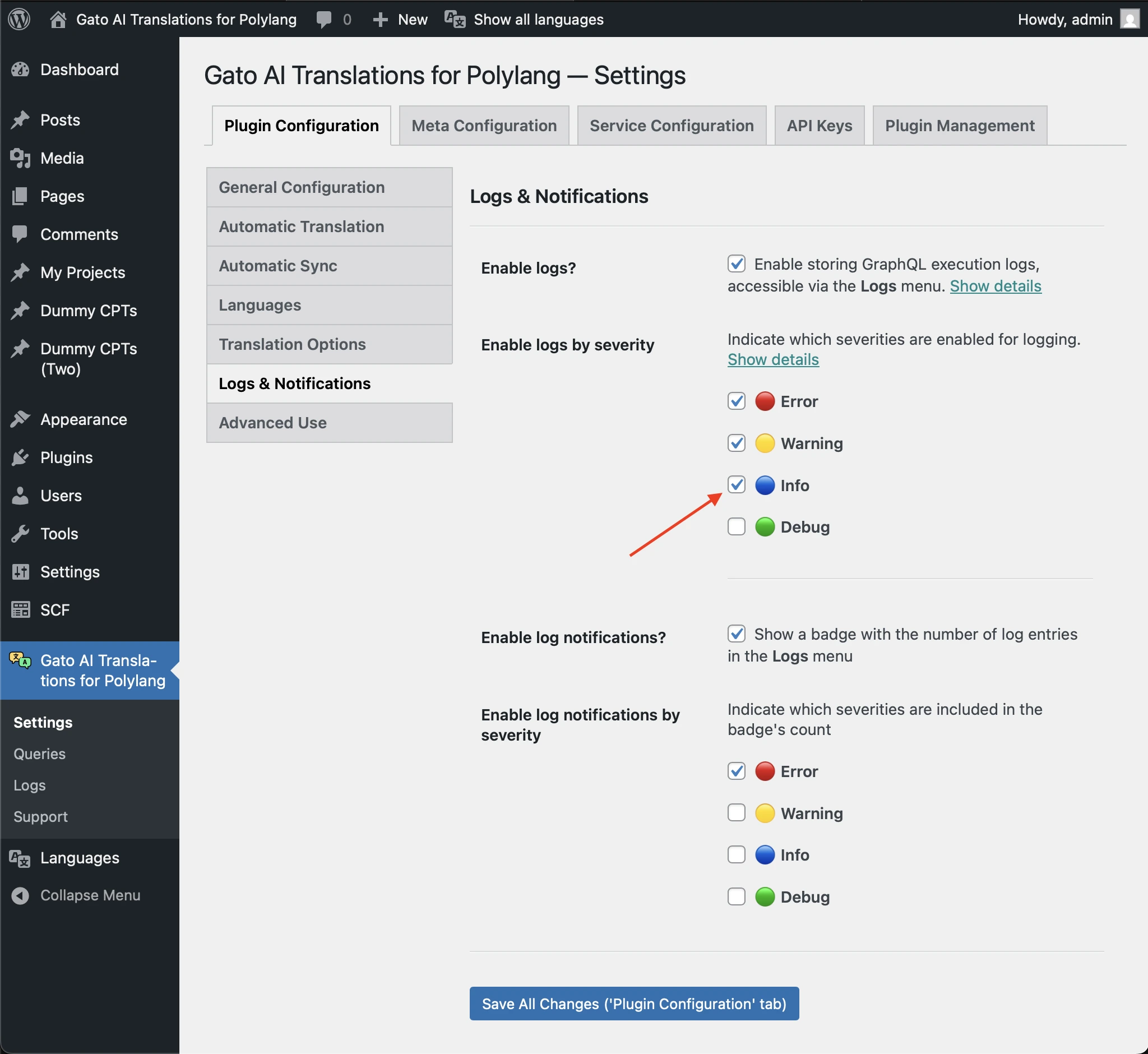
Accessing the AI Requests Logs
The logs will be stored under the ai-requests entries.
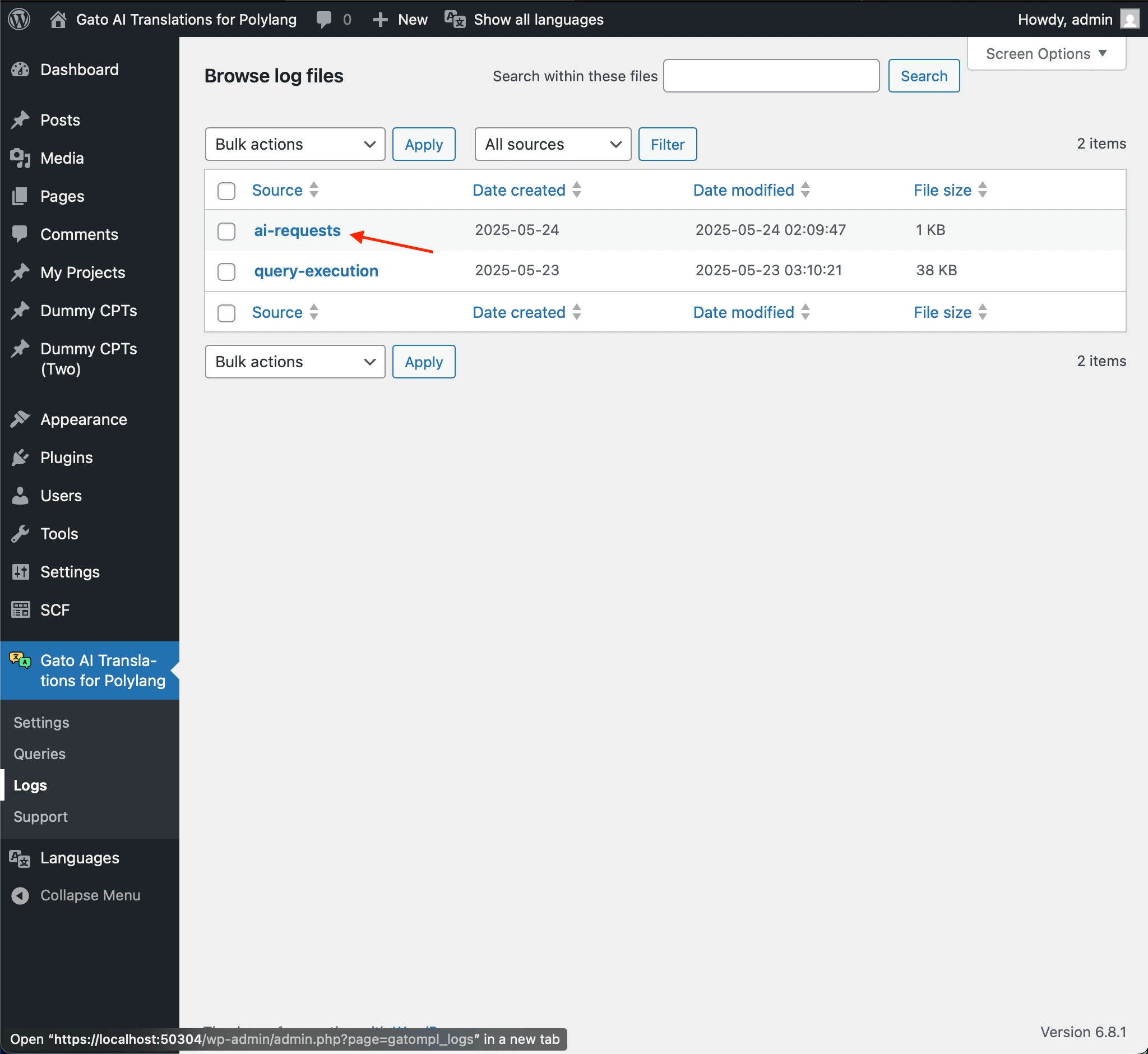
What's Logged
The ai-requests entry contains detailed information about:
- The prompt sent to the AI provider
- The complete response received
- Any errors or issues during the communication
- The model used
- The number of tokens used
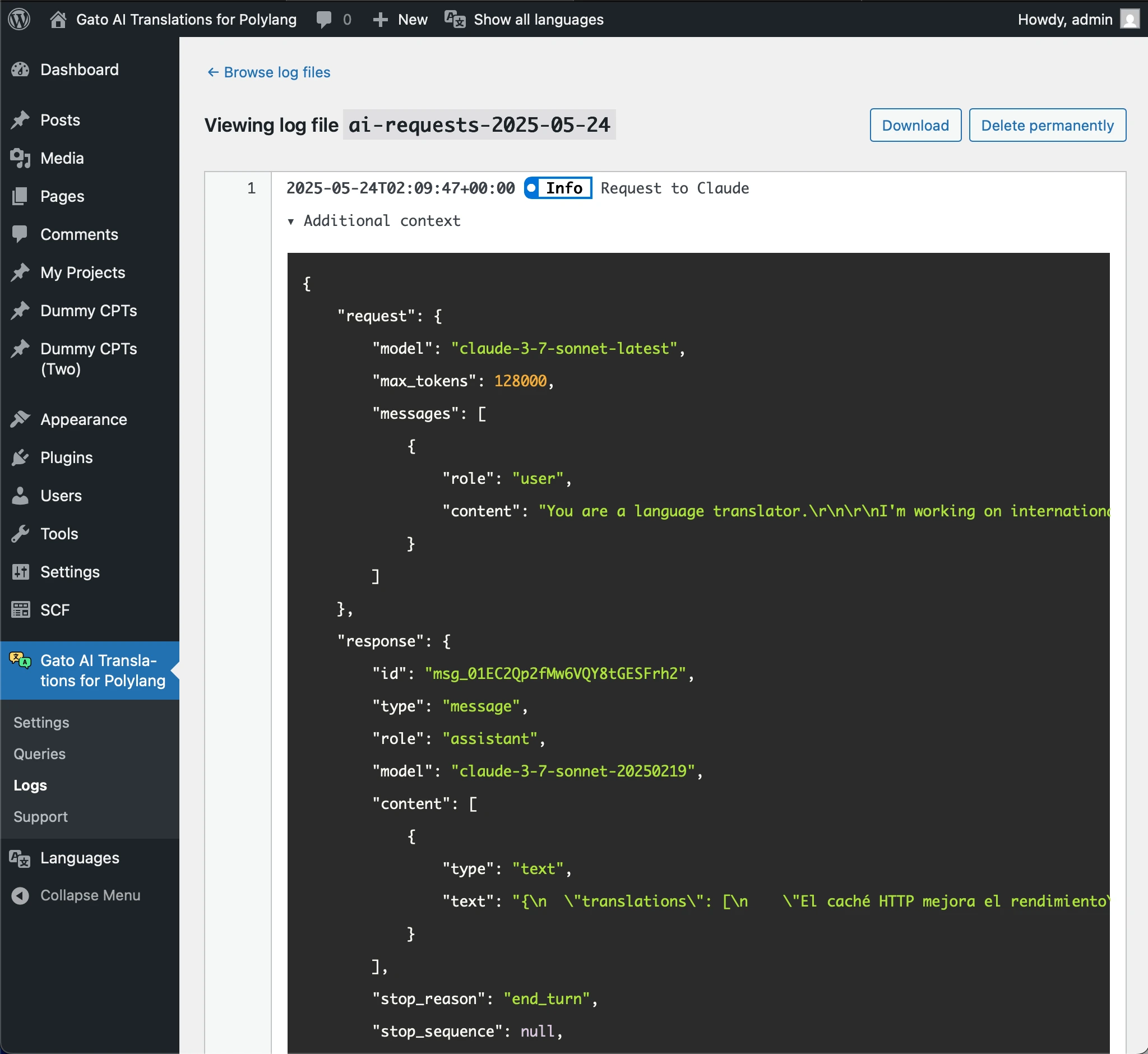
For instance, the following "Additional context" JSON shows the details of a request sent to Claude, and its response:
{
"request": {
"model": "claude-3-7-sonnet-latest",
"max_tokens": 128000,
"messages": [
{
"role": "user",
"content": "You are a language translator.\r\n\r\nI'm working on internationalizing my application.\r\n\r\nI've created a JSON with sentences in English. Please translate the sentences to Spanish from Argentina.\r\n\r\nIf a sentence contains HTML, do not translate inside the HTML tags.\n\nReturn ONLY a JSON object with a single key \"translations\" containing an array of translated strings.\nDo not include any explanations, markdown formatting, or code blocks.\nThe response must be a valid JSON object starting with { and ending with }.\n\nThis is the JSON:\n\n[\"HTTP caching improves performance\",\"Categories Block\",\"Latest Posts Block\",\"Democratizing publishing\"]"
}
]
},
"response": {
"id": "msg_01EC2Qp2fMw6VQY8tGESFrh2",
"type": "message",
"role": "assistant",
"model": "claude-3-7-sonnet-20250219",
"content": [
{
"type": "text",
"text": "{\n \"translations\": [\n \"El caché HTTP mejora el rendimiento\",\n \"Bloque de categorías\",\n \"Bloque de entradas recientes\",\n \"Democratizando la publicación\"\n ]\n}"
}
],
"stop_reason": "end_turn",
"stop_sequence": null,
"usage": {
"input_tokens": 138,
"cache_creation_input_tokens": 0,
"cache_read_input_tokens": 0,
"output_tokens": 61,
"service_tier": "standard"
}
}
}